Rust: Toàn tập về Ownership
Ownership - hệ thống quản lý bộ nhớ không cần garbage collector nhưng vẫn đảm bảo an toàn tuyệt đối. Khác biệt từ cốt lõi này khiến Rust vừa mạnh mẽ như C++, lại vừa an toàn như Go hay C#

Ownership là tính năng độc đáo nhất của Rust và có những tác động sâu sắc đến phần còn lại của ngôn ngữ. Nó cho phép Rust đảm bảo memory safety mà không cần đến garbage collector, vì vậy việc hiểu cách thức hoạt động của ownership là rất quan trọng. Tôi sẽ chủ yếu viết và dịch dựa theo Official Book của Rust, bổ sung thêm một số giải thích và so sánh với một số ngôn ngữ mà tôi đang sử dụng như Go, C# và C++ để giúp các bạn tới từ các ngôn ngữ này có 1 cái nhìn
Chúng ta sẽ nói về ownership cũng như một số tính năng liên quan: borrowing, slices, và cách Rust sắp xếp data trong memory. Trước khi đọc bài này nếu có thể bạn sẽ quan tâm tới Garbage Collection và thuật toán Concurrent Mark-Sweep. Tôi cũng sẽ tách các bài viết về Owenership thành 3 phần như Rust Book
What Is Ownership?
Ownership (Quyền sở hữu) là một tập hợp các quy tắc chi phối cách một chương trình Rust quản lý bộ nhớ. Tất cả các chương trình, khi đang chạy, đều phải quản lý cách chúng sử dụng bộ nhớ của máy tính. Một số ngôn ngữ có garbage collection (bộ thu gom rác) – một tiến trình chạy ngầm, định kỳ tìm kiếm bộ nhớ không còn được sử dụng nữa khi chương trình hoạt động.
Trong các ngôn ngữ như C và C++, lập trình viên phải cấp phát (allocate) và giải phóng (free) bộ nhớ một cách tường minh. Rust sử dụng một cách tiếp cận thứ ba: bộ nhớ được quản lý thông qua một hệ thống ownership với một tập hợp các quy tắc mà compiler (trình biên dịch) sẽ kiểm tra. Nếu bất kỳ quy tắc nào bị vi phạm, chương trình sẽ không thể biên dịch.
Ngược lại, Golang áp dụng một phương pháp khác hẳn để xử lý bộ nhớ: nó trang bị một hệ thống tự động thu gom rác (Garbage Collector). Cơ chế này giúp lập trình viên không cần bận tâm đến việc quản lý bộ nhớ thủ công
Cần lưu ý rằng, cơ chế sở hữu (ownership) này của Rust hoàn toàn không ảnh hưởng đến tốc độ thực thi của ứng dụng bạn. Toàn bộ quá trình kiểm tra được thực hiện trong giai đoạn biên dịch, đảm bảo hiệu suất runtime không bị suy giảm. Đây là một ví dụ kinh điển về triết lý 'zero-cost abstraction'. Bạn có được sự an toàn bộ nhớ ở mức độ cao (như các ngôn ngữ có GC) mà không phải trả giá bằng hiệu năng lúc chạy (runtime performance). Mọi chi phí kiểm tra đều được xử lý ở thời điểm biên dịch
Đối với những lập trình viên đã quen thuộc với các phương pháp quản lý bộ nhớ truyền thống, việc tiếp cận khái niệm ownership của Rust có thể đòi hỏi một quá trình làm quen và điều chỉnh tư duy ban đầu. Tuy nhiên, việc nắm vững các quy tắc của hệ thống ownership sẽ trực tiếp dẫn đến việc phát triển mã nguồn an toàn và tối ưu về hiệu suất. Sự kiên trì trong việc áp dụng các nguyên tắc này là cần thiết để đạt được hiệu quả lập trình cao nhất trong môi trường Rust. Ngoài ra nó còn giúp bạn hiểu thêm về memory để viết code của các ngôn ngữ khác hiệu quả hơn.
Nắm vững cơ chế sở hữu (ownership) là chìa khóa để khai phá sức mạnh và sự độc đáo của Rust. Để minh họa rõ hơn nguyên lý này, chúng ta sẽ khám phá ownership thông qua các ví dụ thực tế, tập trung vào một kiểu dữ liệu quen thuộc và thường gặp: các chuỗi ký tự (strings).
Stack và Heap (The Stack and the Heap)
Nhiều ngôn ngữ lập trình không yêu cầu bạn phải quan tâm nhiều đến stack (ngăn xếp) và heap (vùng nhớ động). Tuy nhiên, trong ngôn ngữ lập trình hệ thống như Rust, vị trí lưu trữ giá trị (trên stack hay heap) ảnh hưởng trực tiếp đến cách ngôn ngữ hoạt động và các quyết định lập trình của bạn. Các phần của ownership sẽ được mô tả liên quan đến stack và heap trong bài viết này, nên tôi sẽ nhắc lại 1 chút để không gián đoạn quá trình đọc.
Cả stack và heap đều là các phần của bộ nhớ có sẵn cho mã nguồn của bạn sử dụng trong quá trình thực thi chương trình, nhưng chúng được cấu trúc theo những cách khác nhau.
Stack lưu trữ các giá trị theo thứ tự nó nhận được chúng và loại bỏ các giá trị theo thứ tự ngược lại. Điều này được gọi là last in, first out (vào sau, ra trước). Hãy tưởng tượng một chồng đĩa: bạn thêm đĩa vào phía trên và cũng lấy đĩa từ phía trên ra. Việc thêm dữ liệu vào stack gọi là pushing onto the stack, còn lấy dữ liệu ra gọi là popping off the stack. Tất cả dữ liệu được lưu trữ trên stack phải có một kích thước đã biết, cố định. Dữ liệu có kích thước không xác định tại compile time (thời điểm biên dịch) hoặc một kích thước có thể thay đổi phải được lưu trữ trên heap thay thế.
Heap có cấu trúc linh hoạt hơn: khi lưu dữ liệu vào heap, bạn yêu cầu một lượng bộ nhớ cụ thể. Memory allocator (bộ cấp phát bộ nhớ) sẽ tìm một vùng trống đủ lớn, đánh dấu nó là đang được sử dụng, và trả về một pointer (con trỏ) chứa địa chỉ của vùng nhớ đó. Quá trình này được gọi là allocating on the heap và đôi khi được viết tắt là allocating (việc đẩy giá trị lên stack không được coi là allocating). Bởi vì pointer trỏ đến heap có kích thước cố định đã biết, bạn có thể lưu trữ pointer trên stack, nhưng khi bạn muốn truy cập dữ liệu thực, bạn phải follow the pointer để đến được dữ liệu thực. Tưởng tượng như việc đặt bàn tại nhà hàng. Khi đến, bạn báo số người, và nhân viên sẽ tìm bàn phù hợp rồi dẫn bạn đến đó. Nếu ai đó trong nhóm của bạn đến muộn, họ có thể hỏi bạn đã được xếp ở đâu để tìm bạn.
Việc pushing to the stack nhanh hơn allocating on the heap vì không cần tìm kiếm vị trí lưu trữ - vị trí đó luôn nằm ở đỉnh stack. Tương đối, việc cấp phát không gian trên heap đòi hỏi nhiều công việc hơn bởi vì allocator trước tiên phải tìm một không gian đủ lớn để chứa dữ liệu và sau đó thực hiện các thao tác bookkeeping (quản lý) để chuẩn bị cho lần cấp phát tiếp theo.
Truy cập dữ liệu trong heap chậm hơn truy cập dữ liệu trên stack bởi vì bạn phải truy theo con trỏ để đến được dữ liệu. Các bộ vi xử lý đương thời hoạt động nhanh hơn nếu chúng ít phải "nhảy" lung tung trong bộ nhớ. Tiếp tục với phép ẩn dụ, hãy xem xét một người phục vụ tại một nhà hàng nhận đơn đặt hàng từ nhiều bàn. Hiệu quả nhất là lấy tất cả các đơn đặt hàng tại một bàn trước khi chuyển sang bàn tiếp theo. Việc lấy một đơn đặt hàng từ bàn A, sau đó một đơn đặt hàng từ bàn B, rồi lại một đơn từ A, và sau đó lại một đơn từ B sẽ là một quá trình chậm hơn nhiều. Tương tự như vậy, một bộ vi xử lý có thể thực hiện công việc của mình tốt hơn nếu nó làm việc trên dữ liệu gần với dữ liệu khác (như trên stack) thay vì ở xa hơn (như có thể có trên heap).
Khi code của bạn gọi một function (hàm), các giá trị được truyền vào hàm (bao gồm cả các pointer trỏ đến dữ liệu trên heap) và các biến cục bộ của hàm sẽ được đẩy vào stack. Khi hàm kết thúc, những giá trị này sẽ được lấy ra khỏi stack.
Việc theo dõi những phần nào của code đang sử dụng dữ liệu nào trên heap, giảm thiểu lượng dữ liệu trùng lặp trên heap, và dọn dẹp dữ liệu không sử dụng trên heap để bạn không hết dung lượng là tất cả các vấn đề mà ownership giải quyết. Khi đã hiểu rõ về ownership (quyền sở hữu), bạn sẽ không cần phải nghĩ nhiều về stack và heap nữa. Tuy nhiên, việc hiểu rằng mục đích chính của ownership là quản lý dữ liệu trên heap sẽ giúp bạn hiểu rõ hơn về cơ chế hoạt động của nó.
Các Quy tắc Ownership (Ownership Rules)
Đầu tiên, hãy xem xét các quy tắc ownership. Hãy ghi nhớ những quy tắc này khi chúng ta làm việc qua các ví dụ minh họa chúng:
Mỗi giá trị trong Rust có một owner (chủ sở hữu).
Chỉ có thể có một owner tại một thời điểm.
Khi owner ra khỏi scope (phạm vi), giá trị sẽ bị dropped (hủy bỏ).
Phạm vi Biến (Variable Scope)
Ví dụ đầu tiên về ownership, chúng ta sẽ xem xét scope của một số biến. Một scope là phạm vi trong một chương trình mà một item (mục, phần tử) là hợp lệ. Lấy ví dụ biến sau:
let s = "hello";Biến s tham chiếu đến một string literal (chuỗi ký tự cố định), tức là giá trị của chuỗi được hardcoded (mã hóa cứng) trực tiếp vào trong mã nguồn của chương trình. Biến này sẽ hợp lệ từ thời điểm nó được khai báo cho đến khi kết thúc scope hiện tại. Listing 4-1 minh họa một chương trình kèm theo các chú thích, chỉ rõ phạm vi hợp lệ của biến s.
{ // s chưa hợp lệ ở đây, nó chưa được khai báo
let s = "hello"; // s hợp lệ từ điểm này trở đi
// làm việc gì đó với s
} // scope này bây giờ đã kết thúc, s không còn hợp lệ nữaListing 4-1: Một biến và scope mà trong đó nó hợp lệ
Nói cách khác, có hai thời điểm quan trọng cần lưu ý:
Khi biến s đi vào scope, nó trở nên hợp lệ.
Biến đó vẫn hợp lệ cho đến khi nó ra khỏi scope.
Ở điểm này, mối quan hệ giữa các scopes và thời gian biến hợp lệ tương tự như trong các ngôn ngữ lập trình khác. Giờ đây, chúng ta sẽ dựa trên sự hiểu biết này để tiếp tục với việc giới thiệu kiểu String.
Kiểu String (The String Type)
Để minh họa các quy tắc về ownership, chúng ta cần một kiểu dữ liệu phức tạp hơn so với những kiểu đã được đề cập trong phần "Data Types" (Các Kiểu Dữ Liệu) của Chương 3. Những kiểu dữ liệu trước đó có kích thước cố định, có thể được lưu trên stack và sẽ được popped off the stack khi phạm vi (scope) của chúng kết thúc. Đồng thời, chúng cũng có thể được sao chép nhanh chóng và đơn giản để tạo ra một instance mới, độc lập, trong trường hợp một phần khác của code cần sử dụng cùng một giá trị trong một scope khác. Tuy nhiên, lần này chúng ta muốn xem xét dữ liệu được lưu trữ trên heap và tìm hiểu cách Rust biết khi nào cần dọn dẹp dữ liệu đó. Kiểu String chính là một ví dụ rất phù hợp cho điều này.
Chúng ta sẽ tập trung vào những phần của String liên quan đến ownership. Những khía cạnh này cũng áp dụng cho các kiểu dữ liệu phức tạp khác, dù chúng được cung cấp bởi standard library (thư viện chuẩn) hay do chính bạn tự tạo ra. Phần thảo luận chi tiết hơn về String sẽ được đề cập trong Chương 8.
Trước đây, chúng ta đã biết về string literals, tức là những giá trị chuỗi được hardcoded trực tiếp trong chương trình. String literals rất tiện lợi, nhưng không phải lúc nào cũng phù hợp với mọi trường hợp khi chúng ta muốn sử dụng văn bản. Một lý do là chúng immutable (bất biến). Một lý do khác là không phải tất cả các giá trị chuỗi đều có thể biết trước khi viết code (tại compile time). Ví dụ, nếu chúng ta muốn lấy user input (đầu vào của người dùng) và lưu trữ nó thì sao? Trong những trường hợp này, Rust cung cấp một kiểu chuỗi thứ hai gọi là String. Kiểu này quản lý dữ liệu được cấp phát trên heap, nhờ vậy có thể lưu trữ lượng văn bản mà chúng ta không biết trước khi compile. Bạn có thể tạo một String từ một string literal bằng cách sử dụng hàm from, ví dụ như sau:
let s = String::from("hello");Toán tử hai dấu hai chấm (::) cho phép chúng ta đặt tên cho hàm from cụ thể này trong namespace (không gian tên) của kiểu String thay vì sử dụng một cái tên nào đó như string_from. Chúng ta sẽ thảo luận thêm về cú pháp này trong phần "Method Syntax" (Cú pháp Phương thức), và khi chúng ta nói về namespacing với modules (mô-đun).
Loại chuỗi này có thể được mutated (thay đổi được):
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() nối một literal vào một String
println!("{s}"); // Dòng này sẽ in ra `hello, world!`Vậy, sự khác biệt ở đây là gì? Tại sao String có thể được thay đổi nhưng literals thì không? Sự khác biệt nằm ở cách Rust xử lý hai kiểu dữ liệu này trong bộ nhớ.
Bộ nhớ và Cấp phát (Memory and Allocation)
Với string literal, nội dung đã được xác định ngay tại thời điểm biên dịch, nên đoạn text này sẽ được nhúng trực tiếp vào file thực thi cuối cùng. Đây chính là lý do khiến string literal có tốc độ xử lý nhanh và hiệu quả. Tuy nhiên, ưu điểm này chỉ có được nhờ tính chất bất biến (immutability) của string literal. Một hạn chế là chúng ta không thể nhúng sẵn vào file nhị phân những khối bộ nhớ chứa văn bản có kích thước không xác định khi biên dịch, hoặc có thể thay đổi kích thước trong lúc chương trình đang chạy.
Với kiểu String - khi cần hỗ trợ văn bản có thể thay đổi (mutable) và mở rộng (growable), chúng ta phải cấp phát một vùng nhớ trên heap mà kích thước không xác định được lúc biên dịch. Điều này dẫn đến hai hệ quả quan trọng:
Bộ nhớ phải được xin cấp phát từ memory allocator khi chương trình chạy (runtime)
Cần cơ chế để hoàn trả bộ nhớ cho allocator sau khi sử dụng xong String
Phần đầu (cấp phát) do chúng ta chủ động thực hiện: khi gọi String::from, implementation sẽ tự động yêu cầu lượng bộ nhớ cần thiết - cách làm phổ biến ở hầu hết ngôn ngữ lập trình.
Phần thứ hai (giải phóng) thì phức tạp hơn:
Ở ngôn ngữ có garbage collector (GC) như Go hay C#, GC tự động theo dõi và thu hồi bộ nhớ không dùng đến
Ở ngôn ngữ không có GC (C/C++), lập trình viên phải tự: • Xác định thời điểm bộ nhớ không còn sử dụng • Chủ động gọi lệnh giải phóng (explicitly free) • Ví dụ: free() sau malloc() trong C, delete sau new trong C++, hay dùng IDisposable/using với unmanaged resources trong C#
Việc quản lý bộ nhớ thủ công từng là bài toán khó:
Quên free → memory leak
Free quá sớm → invalid variable/dangling pointer
Free hai lần → bug nghiêm trọng
Yêu cầu phải khớp chính xác 1 lần allocate với 1 lần free
Rust giải quyết vấn đề quản lý bộ nhớ bằng một cách tiếp cận rất độc đáo: bộ nhớ sẽ tự động được trả lại khi chủ sở hữu (owner) của biến ra khỏi phạm vi (scope). Ví dụ, trong đoạn code dưới đây (tương tự Listing 4-1, nhưng với kiểu String thay vì string literal):
{
let s = String::from("hello"); // s hợp lệ từ điểm này trở đi
// làm việc gì đó với s
} // scope này bây giờ đã kết thúc, s không còn hợp lệ nữa (và bộ nhớ của nó được giải phóng)Khi biến s ra khỏi phạm vi, Rust sẽ tự động giải phóng bộ nhớ mà String đã sử dụng. Điều này được thực hiện thông qua một hàm đặc biệt gọi là drop. Hàm này cho phép định nghĩa cách dọn dẹp và trả lại bộ nhớ cho bộ cấp phát (allocator) khi một kiểu dữ liệu (như String) không còn sử dụng nữa. Rust sẽ tự động gọi hàm drop ngay khi phạm vi của biến kết thúc, tức là khi dấu ngoặc nhọn đóng } xuất hiện.
Lưu ý: Trong C++, mô hình giải phóng tài nguyên vào cuối vòng đời của một đối tượng thường được gọi là Resource Acquisition Is Initialization (RAII). Nếu bạn đã từng dùng RAII, thì hàm drop trong Rust sẽ rất quen thuộc. Ví dụ, khi một đối tượng C++ ra khỏi phạm vi, destructor (hàm hủy) của nó được tự động gọi để giải phóng tài nguyên.
Bảng so sánh:
Tính năng | Rust (Ownership) | Go / C# (Garbage Collector) | C / C++ (Manual Management) |
Cơ chế | Compiler theo dõi "owner" và tự động giải phóng bộ nhớ khi ra khỏi scope. | Một tiến trình ngầm (GC) định kỳ quét và dọn dẹp bộ nhớ không còn được tham chiếu. | Phải gọi |
Hiệu năng | Không có overhead lúc chạy (runtime). An toàn được đảm bảo lúc biên dịch (compile-time). | Có thể gây ra những khoảng dừng nhỏ (latency spikes) khi GC chạy. | Performance tốt nhất (nếu làm đúng), nhưng dễ gây lỗi. |
Rủi ro | learning curve dốc, code có thể dài dòng hơn ban đầu. | Không thể kiểm soát thời điểm bộ nhớ được giải phóng. | Memory leaks, double free, dangling pointers. |
Cách tiếp cận này của Rust tạo ra một khuôn mẫu lập trình đặc thù, có ảnh hưởng sâu rộng đến từng dòng code bạn viết. Dù trông có vẻ đơn giản, nhưng khi đối mặt với các kịch bản phức tạp – đặc biệt là khi nhiều tham chiếu cùng chia sẻ quyền truy cập vào một vùng dữ liệu trên heap – sự tương tác giữa các biến có thể trở nên khó lường. Để làm rõ hơn những tình huống này, chúng ta sẽ đi sâu vào phân tích các trường hợp cụ thể để làm rõ vấn đề này.
Biến và Dữ liệu Tương tác với Move (Move)
Nhiều biến có thể tương tác với cùng một dữ liệu theo những cách khác nhau trong Rust. Hãy xem một ví dụ sử dụng một số nguyên trong Listing 4-2.
let x = 5;
let y = x;Listing 4-2: Gán giá trị số nguyên của biến x cho y
Chúng ta có thể hiểu đoạn này như sau: "Gán giá trị 5 cho biến x; sau đó tạo một bản sao của giá trị trong x và gán nó cho biến y." Kết quả là ta có hai biến, x và y, đều mang giá trị 5. Điều này xảy ra vì các số nguyên là kiểu dữ liệu đơn giản, có kích thước cố định và được lưu trữ trực tiếp trên stack. Do đó, khi gán, giá trị được sao chép nguyên vẹn lên stack cho biến mới.
Bây giờ hãy xem ví dụ với kiểu String:
let s1 = String::from("hello");
let s2 = s1;Trông có vẻ giống với ví dụ trước, nên ta có thể nghĩ rằng dòng thứ hai sẽ tạo một bản sao của giá trị trong s1 và gán nó cho s2. Tuy nhiên, thực tế không hoàn toàn như vậy.
Hãy xem Hình 4-1 để hiểu rõ hơn về cách hoạt động “behind the scene” của một String. Một String bao gồm ba phần chính (được hiển thị bên trái hình): một con trỏ (pointer) trỏ tới vùng bộ nhớ chứa nội dung chuỗi trên heap, một trường length (độ dài của chuỗi), và một trường capacity (sức chứa bộ nhớ đã cấp phát). Ba phần dữ liệu này được lưu trữ trên stack. Còn ở bên phải là vùng bộ nhớ trên heap chứa nội dung thực tế của chuỗi.
")
(Hình 4-1: Biểu diễn trong bộ nhớ của một String giữ giá trị "hello" được gán cho s1)
Bên trái (Stack):
name: s1
ptr: (địa chỉ trỏ đến vùng nhớ trên heap)
len: 5 (số byte hiện đang sử dụng cho "hello")
cap: 5 (tổng số byte bộ nhớ đã nhận từ allocator cho chuỗi này)
Bên phải (Heap):
index: 0 1 2 3 4
value: h e l l o
length là lượng bộ nhớ, tính theo byte, mà nội dung của String hiện đang sử dụng. Còn capacity là tổng lượng bộ nhớ, cũng tính theo byte, mà String đã được cấp phát từ allocator. Sự khác biệt giữa length và capacity rất quan trọng, nhưng tạm thời chúng ta có thể bỏ qua capacity. Trong Go, một slice cũng có hai thuộc tính tương tự là length và capacity; trong đó capacity là kích thước của mảng cơ sở mà slice trỏ tới, bắt đầu từ phần tử đầu tiên của slice.
Khi chúng ta gán s1 cho s2 bằng câu lệnh let s2 = s1;, toàn bộ dữ liệu của String (tức là cấu trúc chứa con trỏ, độ dài và sức chứa) được sao chép. Điều này có nghĩa là chúng ta sao chép con trỏ, length và capacity nằm trên stack, chứ không sao chép dữ liệu thực tế trên heap mà con trỏ đó trỏ tới. Nói cách khác, cấu trúc dữ liệu trong bộ nhớ sẽ giống như mô tả trong Hình 4-2.
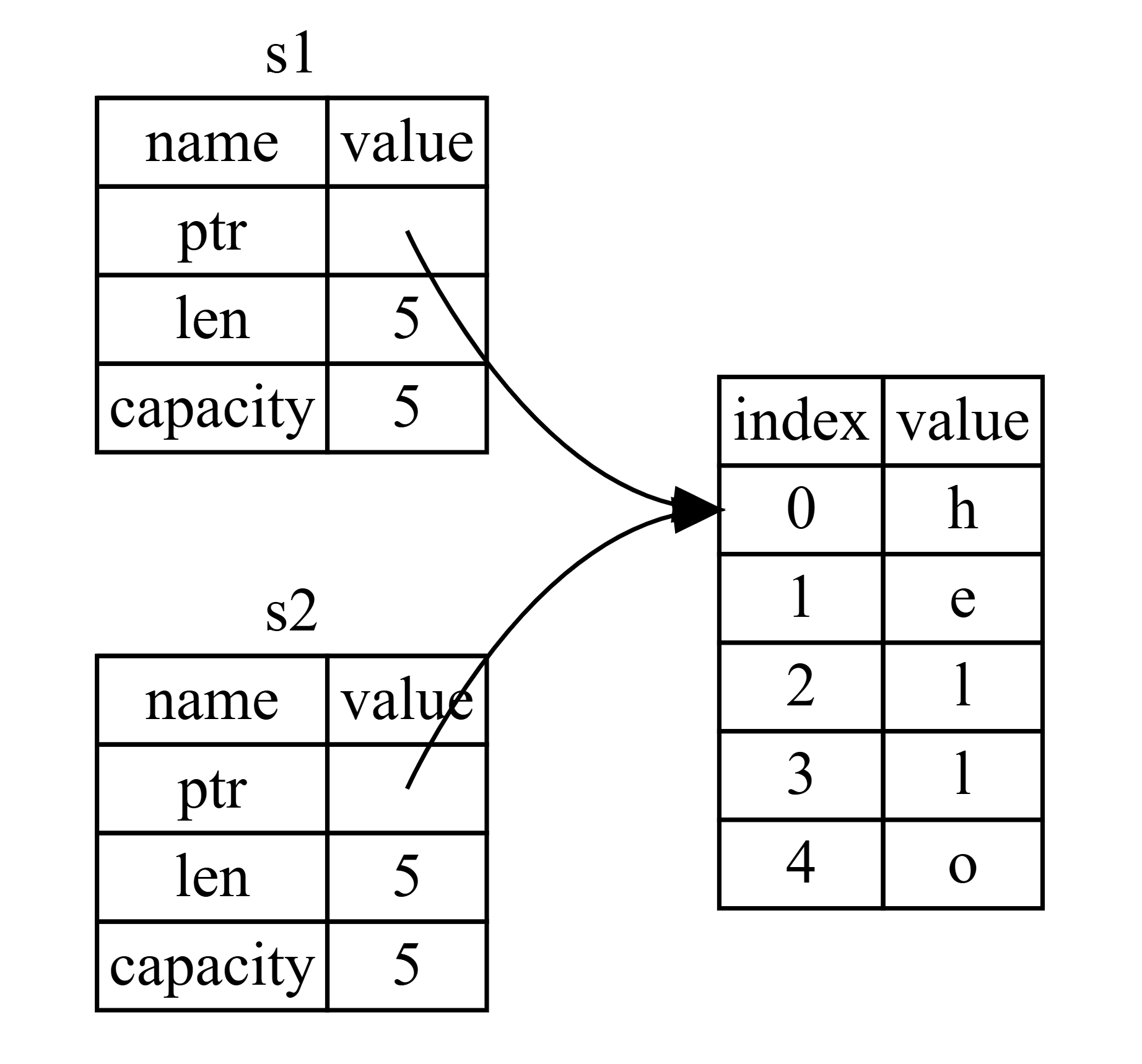
(Hình 4-2: Biểu diễn trong bộ nhớ của biến s2 có một bản sao của pointer, length, và capacity của s1)
Stack:
s1: ptr (trỏ đến "hello" trên heap), len: 5, cap: 5
s2: ptr (trỏ đến cùng "hello" trên heap), len: 5, cap: 5
Heap:
Dữ liệu "hello" (chỉ có một bản)
Hình 4-3 là hình ảnh minh họa nếu Rust sao chép cả dữ liệu trên heap khi thực hiện gán s2 = s1. Nếu Rust làm như vậy, thao tác này sẽ rất tốn kém về hiệu năng khi dữ liệu trên heap lớn.
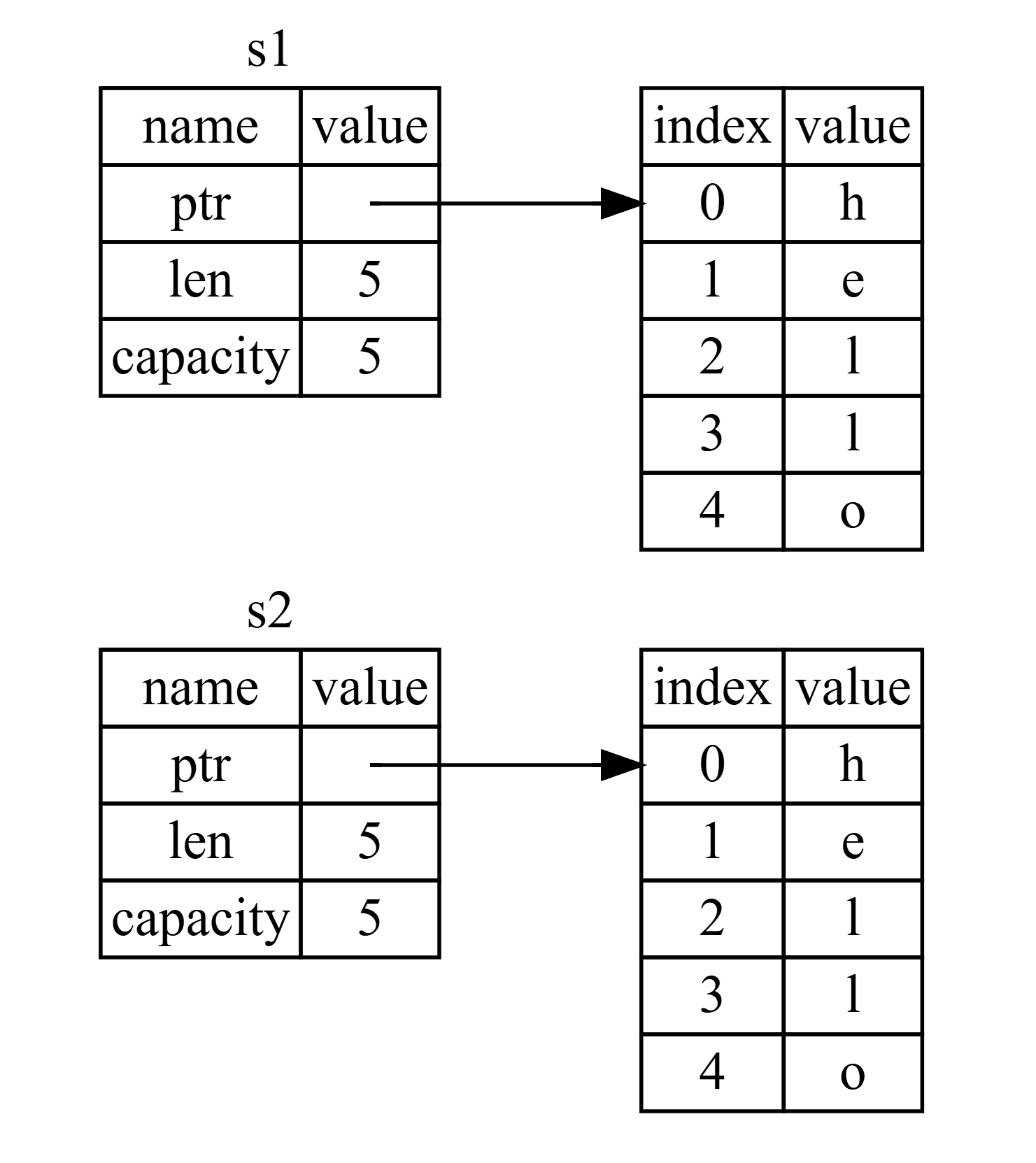
(Hình 4-3: Một khả năng khác cho những gì s2 = s1 có thể làm nếu Rust cũng sao chép dữ liệu heap)
Stack:
s1: ptr1 (trỏ đến bản sao "hello" thứ nhất trên heap), len: 5, cap: 5
s2: ptr2 (trỏ đến bản sao "hello" thứ hai trên heap), len: 5, cap: 5
Heap:
Bản sao "hello" thứ nhất
Bản sao "hello" thứ hai
Trước đó, chúng ta đã nói rằng khi một biến ra khỏi scope, Rust tự động gọi hàm drop và dọn dẹp bộ nhớ heap cho biến đó. Nhưng Hình 4-2 cho thấy cả hai pointer dữ liệu đều trỏ đến cùng một vị trí. Lúc này phát sinh một vấn đề: khi s2 và s1 ra khỏi scope, cả hai sẽ cố gắng giải phóng cùng một bộ nhớ. Đây chính là một lỗi double free (giải phóng kép) và là một trong những bug về memory safety mà chúng ta đã đề cập ở trên. Giải phóng bộ nhớ hai lần có thể dẫn đến memory corruption, tạo ra các lỗ hổng bảo mật (security vulnerabilities). Đây là một vấn đề nghiêm trọng trong C/C++ nếu không quản lý cẩn thận.
Để đảm bảo an toàn bộ nhớ, sau dòng let s2 = s1;, Rust coi s1 là không còn hợp lệ nữa. Do đó, Rust không cần phải giải phóng bất cứ thứ gì khi s1 ra khỏi scope. Hãy xem điều gì xảy ra khi bạn cố gắng sử dụng s1 sau khi s2 được tạo; nó sẽ không hoạt động:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Lỗi! s1 đã bị moveBạn sẽ nhận được một lỗi như sau bởi vì Rust ngăn bạn sử dụng tham chiếu đã bị vô hiệu hóa:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1` --> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous errorNếu bạn đã từng nghe về các khái niệm shallow copy (sao chép nông) và deep copy (sao chép sâu) trong các ngôn ngữ khác, thì việc sao chép con trỏ, độ dài (length) và sức chứa (capacity) mà không sao chép dữ liệu thực tế có thể coi như một shallow copy. Ví dụ, trong C#, khi bạn gán một biến kiểu tham chiếu (reference type) cho một biến khác, bạn đang thực hiện shallow copy — tức là cả hai biến đều trỏ đến cùng một đối tượng trên heap. Tương tự, trong Go, việc gán một slice hoặc map cũng chỉ là sao chép nông cấu trúc mô tả (descriptor), không phải dữ liệu bên dưới.
Tuy nhiên, trong Rust, sau khi gán, biến ban đầu không còn hợp lệ nữa (bị vô hiệu hóa). Vì vậy, thay vì gọi đây là shallow copy, người ta gọi đó là move (di chuyển). Trong ví dụ này, ta nói rằng giá trị của s1 đã được moved sang s2. Những gì thực sự xảy ra được minh họa trong Hình 4-4.
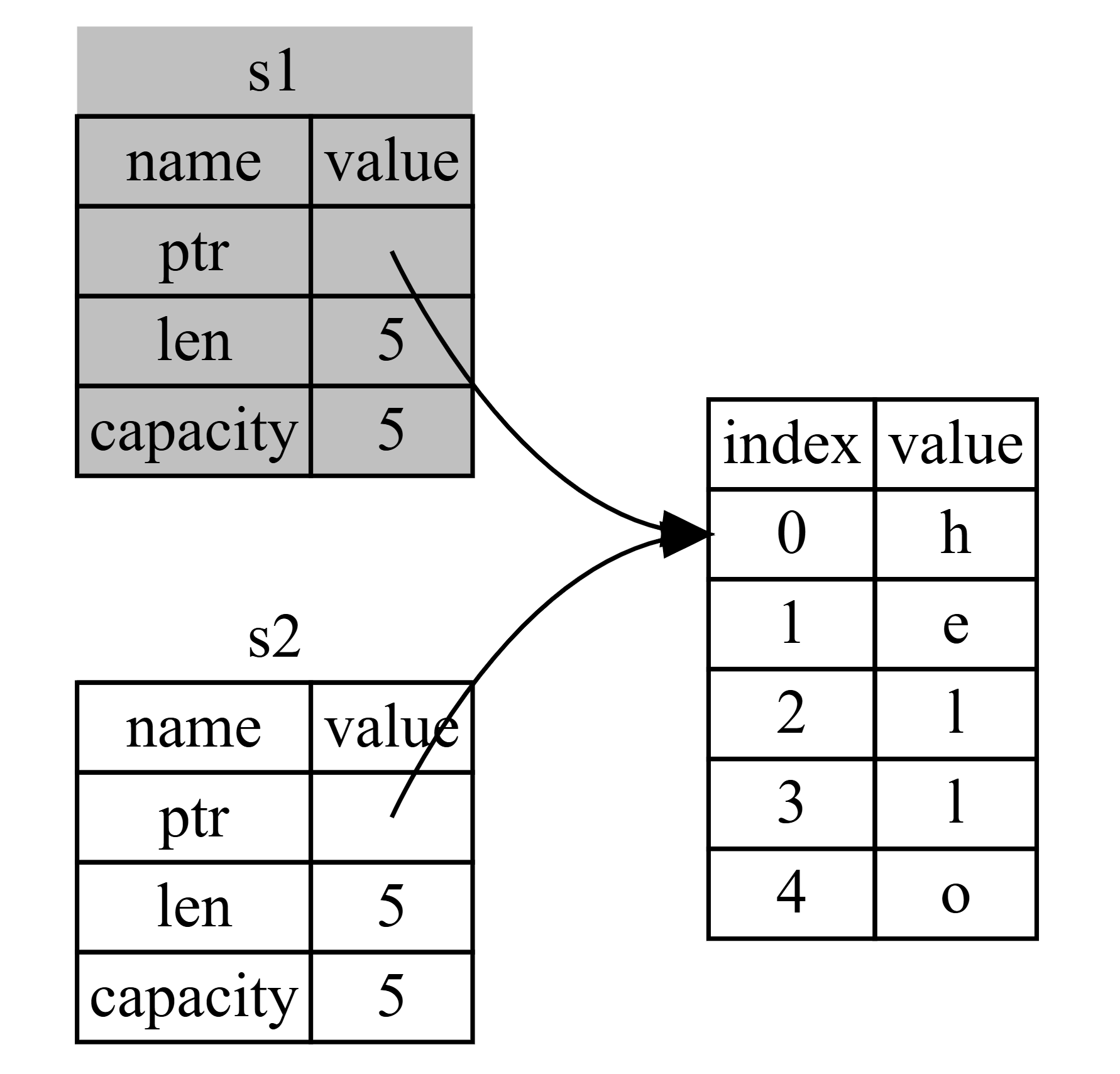
(Hình 4-4: Biểu diễn trong bộ nhớ sau khi s1 đã bị vô hiệu hóa)
Stack:
s1: (không hợp lệ/không trỏ tới đâu cả)
s2: ptr (trỏ đến "hello" trên heap), len: 5, cap: 5
Heap:
Dữ liệu "hello"
Điều này giải quyết được vấn đề của chúng ta! Chỉ có s2 là hợp lệ, và khi s2 ra khỏi phạm vi (scope), chính nó sẽ chịu trách nhiệm giải phóng bộ nhớ, giúp tránh được việc giải phóng bộ nhớ nhiều lần hoặc rò rỉ bộ nhớ.
Ngoài ra, thiết kế này còn ngụ ý một nguyên tắc quan trọng: Rust không bao giờ tự động tạo các bản sao "sâu" (deep copies) của dữ liệu. Do đó, bất kỳ thao tác sao chép tự động nào trong Rust đều có thể được giả định là rất nhẹ về mặt hiệu năng trong runtime. Điều này khác biệt so với một số ngôn ngữ như C++, nơi các toán tử gán hoặc hàm khởi tạo sao chép (copy constructors) có thể thực hiện deep copy một cách ngầm định, dẫn đến chi phí hiệu năng không rõ ràng.
Phạm vi và Gán (Scope and Assignment)
Nguyên tắc ngược lại của việc move cũng đúng với mối quan hệ giữa phạm vi (scope), ownership và việc giải phóng bộ nhớ qua hàm drop. Khi bạn gán một giá trị mới hoàn toàn cho một biến đã tồn tại, Rust sẽ gọi drop để giải phóng bộ nhớ của giá trị cũ ngay lập tức trước khi gán giá trị mới.
let mut s = String::from("hello"); // s được gán "hello"
s = String::from("ahoy"); // s bây giờ được gán "ahoy", "hello" bị drop
println!("{}, world!", s);Chúng ta ban đầu khai báo một biến s và gán nó cho một String với giá trị "hello". Sau đó, chúng ta ngay lập tức tạo một String mới với giá trị "ahoy" và gán nó cho s. Tại thời điểm này, không có gì tham chiếu đến giá trị ban đầu ("hello") trên heap cả.
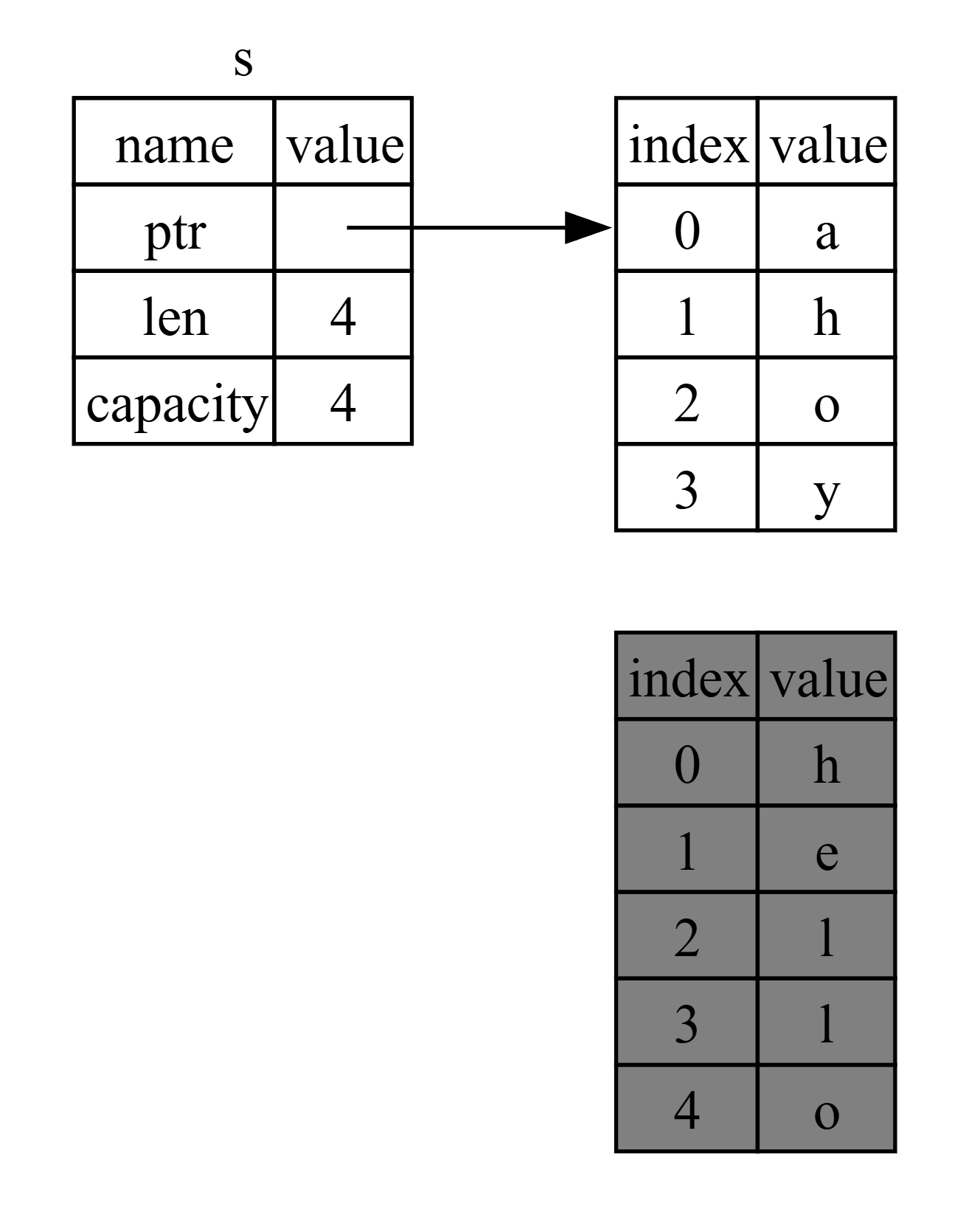
(Hình 4-5: Biểu diễn trong bộ nhớ sau khi giá trị ban đầu đã được thay thế hoàn toàn.)
Bước 1: let mut s = String::from("hello");
Stack: s -> ptr1, len: 5, cap: 5
Heap: ptr1 -> "hello"
Bước 2: s = String::from("ahoy");
Bộ nhớ của "hello" (trỏ bởi ptr1) được drop.
Stack: s -> ptr2, len: 4, cap: 4
Heap: ptr2 -> "ahoy"
Chuỗi ban đầu ("hello") do đó ngay lập tức ra khỏi scope (vì không còn owner nào). Rust sẽ chạy hàm drop trên nó và bộ nhớ của nó sẽ được giải phóng ngay lập tức. Khi chúng ta in giá trị ở cuối, nó sẽ là "ahoy, world!".
Biến và Dữ liệu Tương tác với Clone
Nếu chúng ta thực sự muốn sao chép sâu (deeply copy) dữ liệu trên heap của String, không chỉ sao chép dữ liệu trên stack, chúng ta có thể sử dụng phương thức phổ biến gọi là clone. Chúng ta sẽ thảo luận về cú pháp phương thức trong các bài viết sau, nhưng vì phương thức này là một tính năng phổ biến trong nhiều ngôn ngữ lập trình, bạn có thể đã từng gặp trước đó. Ví dụ, trong C#, nhiều lớp triển khai giao diện ICloneable để thực hiện mục đích tương tự, hoặc bạn có thể viết các hàm sao chép tùy chỉnh. Trong Go, bạn thường phải tự viết hàm để thực hiện deep copy cho các kiểu dữ liệu phức tạp.
Dưới đây là ví dụ minh họa phương thức clone hoạt động:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");Điều này hoạt động hiệu quả và thể hiện rõ hành vi như trong Hình 4-3, nơi dữ liệu trên heap thực sự được sao chép.
Khi bạn thấy một lời gọi đến clone, bạn biết rằng một đoạn mã phức tạp đang được thực thi và có thể tốn kém tài nguyên. Đây là dấu hiệu rõ ràng cho thấy có điều gì đó khác biệt đang xảy ra.
Dữ liệu Chỉ trên Stack: Copy
Có một điểm nữa mà chúng ta chưa đề cập đến. Đoạn code này sử dụng số nguyên — một phần trong đó đã được trình bày ở Listing 4-2 — hoạt động và hợp lệ:
let x = 5;
let y = x;
println!("x = {x}, y = {y}");Nhưng nó dường như mâu thuẫn với những gì chúng ta vừa học: chúng ta không có lệnh gọi đến clone, nhưng x vẫn hợp lệ và không bị move vào y.
Lý do là các kiểu như số nguyên có kích thước đã biết tại compile time được lưu trữ hoàn toàn trên stack, vì vậy việc tạo bản sao của các giá trị thực tế rất nhanh chóng. Điều đó có nghĩa là không có lý do gì chúng ta muốn ngăn x không hợp lệ sau khi chúng ta tạo biến y. Nói cách khác, không có sự khác biệt giữa deep copying và shallow copying ở đây, vì vậy việc gọi clone sẽ không làm gì khác với việc sao chép nông thông thường, và chúng ta có thể bỏ qua nó. Điều này tương tự như cách các value types (kiểu giá trị) như int, float, struct trong C# được sao chép khi gán, hoặc các kiểu cơ bản và structs trong Go.
Rust có một annotation (chú thích) đặc biệt được gọi là Copy trait mà chúng ta có thể đặt trên các kiểu được lưu trữ trên stack, như các số nguyên (chúng ta sẽ nói thêm về traits trong Chương 10). Nếu một kiểu triển khai (implements) Copy trait, các biến sử dụng nó không move, mà thay vào đó được sao chép một cách tầm thường (trivially copied), làm cho chúng vẫn hợp lệ sau khi gán cho một biến khác.
Rust sẽ không cho phép chúng ta chú thích một kiểu với Copy nếu kiểu đó, hoặc bất kỳ phần nào của nó, đã triển khai Drop trait. Nếu kiểu đó cần một điều gì đó đặc biệt xảy ra khi giá trị ra khỏi scope (nghĩa là nó có Drop trait để quản lý tài nguyên) và chúng ta thêm Copy annotation vào kiểu đó, chúng ta sẽ nhận được lỗi tại compile-time. Để tìm hiểu về cách thêm Copy annotation vào kiểu của bạn để triển khai trait, xem "Derivable Traits" (Các Trait có thể Derive) trong Phụ lục C.
Vậy, những kiểu nào triển khai Copy trait? Bạn có thể kiểm tra tài liệu cho kiểu đã cho để chắc chắn, nhưng theo quy tắc chung, bất kỳ nhóm giá trị vô hướng (scalar) đơn giản nào cũng có thể triển khai Copy, và không có gì yêu cầu cấp phát (trên heap) hoặc là một dạng tài nguyên nào đó có thể triển khai Copy. Dưới đây là một số kiểu triển khai Copy:
Tất cả các kiểu số nguyên, chẳng hạn như u32.
Kiểu Boolean, bool, với các giá trị true và false.
Tất cả các kiểu số thực dấu phẩy động, chẳng hạn như f64.
Kiểu ký tự, char.
Các Tuples (bộ), nếu chúng chỉ chứa các kiểu cũng triển khai Copy. Ví dụ, (i32, i32) triển khai Copy, nhưng (i32, String) thì không.
Tóm gọn lại là:
Copy(Sao chép ngầm định): Dành cho các kiểu dữ liệu "rẻ tiền", chỉ nằm trên Stack. Phép gánlet y = x;sẽ tạo một bản sao đầy đủ vàxvẫn hợp lệ. Đây là hành vi sao chép bit-bit (bitwise copy).Move(Di chuyển ngầm định): Là hành vi mặc định cho các kiểu dữ liệu sở hữu tài nguyên trên Heap (nhưString). Phép gánlet s2 = s1;chỉ sao chép con trỏ trên stack và vô hiệu hóas1để tránh lỗidouble free.Clone(Sao chép tường minh): Khi bạn thực sự muốn tạo một bản sao "sâu" (deep copy) của dữ liệu trên Heap. Bạn phải gọis1.clone()một cách tường minh. Đây là một hành động có thể tốn kém về tài nguyên.
Ownership và Hàm (Ownership and Functions)
Cơ chế truyền một giá trị cho một hàm tương tự như khi gán một giá trị cho một biến. Truyền một biến cho một hàm sẽ move hoặc copy, giống như phép gán. Listing 4-3 có một ví dụ với một số chú thích cho thấy các biến đi vào và ra khỏi scope ở đâu.
File: src/main.rs
fn main() {
let s = String::from("hello"); // s đi vào scope
takes_ownership(s); // giá trị của s move vào hàm...
// ... và do đó không còn hợp lệ ở đây nữa
// println!("{s}"); // Dòng này sẽ gây lỗi biên dịch vì s đã bị move
let x = 5; // x đi vào scope
makes_copy(x); // bởi vì i32 triển khai Copy trait,
// x KHÔNG move vào hàm,
println!("Giá trị của x sau khi gọi makes_copy: {x}"); // vì vậy vẫn ổn khi sử dụng x sau đó
} // Ở đây, x ra khỏi scope, sau đó là s. Nhưng vì giá trị của s đã được move,
// không có gì đặc biệt xảy ra với s (nó đã bị vô hiệu hóa, bộ nhớ của nó
// sẽ được quản lý bởi takes_ownership).
fn takes_ownership(some_string: String) { // some_string đi vào scope
println!("Bên trong takes_ownership: {some_string}");
} // Ở đây, some_string ra khỏi scope và `drop` được gọi. Bộ nhớ đệm
// (backing memory) được giải phóng.
fn makes_copy(some_integer: i32) { // some_integer đi vào scope
println!("Bên trong makes_copy: {some_integer}");
} // Ở đây, some_integer ra khỏi scope. Không có gì đặc biệt xảy ra (vì nó là kiểu Copy).Listing 4-3: Các hàm với ownership và scope được chú thích
Nếu chúng ta cố gắng sử dụng s sau lệnh gọi đến takes_ownership, Rust sẽ đưa ra lỗi tại compile-time. Những kiểm tra tĩnh (static checks) này bảo vệ chúng ta khỏi những sai lầm. Hãy thử thêm code vào main sử dụng s và x để xem bạn có thể sử dụng chúng ở đâu và các quy tắc ownership ngăn bạn làm điều đó ở đâu.
Giá trị Trả về và Scope (Return Values and Scope)
Trả về giá trị cũng có thể chuyển ownership. Listing 4-4 hiển thị một ví dụ về một hàm trả về một số giá trị, với các chú thích tương tự như trong Listing 4-3.
File: src/main.rs
fn main() {
let s1 = gives_ownership(); // gives_ownership move giá trị trả về của nó vào s1
let s2 = String::from("hello"); // s2 đi vào scope
let s3 = takes_and_gives_back(s2); // s2 được move vào takes_and_gives_back, hàm này cũng move giá trị trả về của nó vào s3
// println!("{s2}"); // Lỗi! s2 đã bị move vào takes_and_gives_back
} // Ở đây, s3 ra khỏi scope và bị dropped. s2 đã được move, vì vậy không có gì xảy ra với nó. s1 ra khỏi scope và bị dropped.
fn gives_ownership() -> String { // gives_ownership sẽ move giá trị trả về của nó vào hàm gọi nó
let some_string = String::from("yours"); // some_string đi vào scope
some_string // some_string được trả về và move ra hàm gọi
}
// Hàm này nhận một String và trả về một String
fn takes_and_gives_back(a_string: String) -> String { // a_string đi vào scope
a_string // a_string được trả về và move ra hàm gọi
}Listing 4-4: Chuyển ownership của giá trị trả về
Ownership của một biến tuân theo cùng một mẫu mỗi lần: gán một giá trị cho một biến khác sẽ move nó. Khi một biến bao gồm dữ liệu trên heap ra khỏi scope, giá trị sẽ được dọn dẹp bởi drop trừ khi ownership của dữ liệu đã được move sang một biến khác.
Mặc dù điều này hoạt động, việc nhận ownership và sau đó trả lại ownership với mọi hàm có một chút tẻ nhạt. Nếu chúng ta muốn cho một hàm sử dụng một giá trị nhưng không lấy ownership thì sao? Khá khó chịu khi bất cứ thứ gì chúng ta truyền vào cũng cần phải được truyền lại nếu chúng ta muốn sử dụng lại nó, ngoài bất kỳ dữ liệu nào là kết quả của phần thân hàm mà chúng ta có thể muốn trả về. Điều này giống như trong C, nếu bạn truyền một con trỏ đến một hàm để nó sửa đổi dữ liệu, bạn vẫn giữ quyền sở hữu con trỏ đó. Nhưng ở đây, nếu bạn truyền chính giá trị (và nó không phải là kiểu Copy), bạn mất quyền sở hữu nó.
Rust cho phép chúng ta trả về nhiều giá trị bằng cách sử dụng một tuple, như được hiển thị trong Listing 4-5.
File: src/main.rs
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1); // s1 bị move vào calculate_length calculate_length trả về ownership của chuỗi (giờ là s2) và độ dài
println!("Độ dài của '{s2}' là {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() trả về độ dài của một String
(s, length) // Trả về String (chuyển ownership) và độ dài
}Listing 4-5: Trả lại ownership của tham số
Tuy nhiên, bạn có thể thấy cách tiếp cận này khá rườm rà và đòi hỏi nhiều thao tác cho một khái niệm lẽ ra phải đơn giản hơn. Rõ ràng, việc phải liên tục chuyển đi và nhận lại ownership như thế này thật phiền phức và dài dòng. Làm thế nào để một hàm có thể 'mượn' (borrow) một giá trị để sử dụng mà không cần 'lấy luôn' (take ownership) quyền sở hữu của nó?
Rất may, Rust cung cấp một tính năng cực kỳ mạnh mẽ cho mục đích này: References và Borrowing. Đây chính là mảnh ghép còn lại để hoàn thiện bức tranh về ownership, và chúng ta sẽ khám phá nó trong Phần 2 của loạt bài này.
Comments